
Yksinkertaista järjestelmävisualisointia – Docker HyperKit, DTrace ja gnuplot

Siirryimme n. vuosi sitten ajamaan kehittäjätyöasemillamme paikallisia kehitysympäristöjä Docker-konttien päällä. Tätä ennen käytimme hyvin pitkään VirtualBox-virtuaalikoneita, joita konfiguroimme ja hallinnoimme Vagrantilla. Docker on – varsin odotetusti – osoittautunut käytännöllisemmäksi tavaksi pyörittää paikallisia kehitysympäristöjä, mutta täysin ongelmatonta kehitystyö Dockerin kanssakaan ei ole ollut.
Ylivoimaista valtaosaa kehittäjätyöasemistamme käytetään Applen macOS-käyttöjärjestelmällä. Koska Docker-kontit hydyntävät Linux-ytimen cgroup- ja nimiavaruusominaisuuksia, ei kontteja voida ajaa suoraan macOS:ssä. Tästä syystä macOS:n päällä pitääkin ajaa ensin virtualisoituna ohutta Linux-ydintä, jonka päällä sitten voidaan pyörittää Docker-kontteja. Perinteisestä hypervisorista ja laitteistotason virtualisoinnista ei ihan kokonaan olla siis vielä päästy macOS:n kanssa eroon, mutta ainakaan meidän ei enää tarvitse ajaa jokaista sivustoa omalla Linux-virtuaalikoneellaan.
HyperKit, Dockerin hypervisor
Laitteistotason virtualisoinnissa hypervisorin tehtävänä on toimia eräänlaisena liimakerroksena isäntä- ja vieraskäyttöjärjestelmän välillä niin, että vieraskäyttöjärjestelmä luulee pyörivänsä koneen ainoana käyttöjärjestelmänä. Hypervisor siis käytännössä valehtelee vieraskäyttöjärjestelmälle suun ja silmät täyteen ja vetää verhoa tiukasti isäntäkäyttöjärjestelmän eteen, jotta totuus vieraalle ei paljastu. Siinä missä Vagrantin kanssa käytimme hypervisorina VirtualBoxia, on Dockerin kanssa macOS:llä käytössä HyperKit. HyperKit on Dockerille varta vasten rakennettu komponentti, joka perustuu macOS:n Hypervisor.framework-sovelluskehykseen.
Docker-kontteja ajettaessa macOS:ssä kaikki varsinainen konteissa tehtävät työ näkyy HyperKit-prosessissa (nimellä com.docker.hyperkit). Konttien sisällä tapahtuvan työn lisäksi tähän kuuluu myös kaikki itse hypervisorin toimintaan liittyvä työ. Hypervisor vastaa esimerkiksi tiedostojen synkronoinnista isäntä- ja vieraskäyttöjärjestelmän välillä, mikä saattaakin joissain käyttötapauksissa aiheuttaa merkittävästi prosessorikuormaa.
Ongelmat Docker-kokoonpanomme kanssa
Jokainen käyttämämme kehitysympäristö koostuu useasta kontista, joista kukin hoitaa oman osa-alueensa:
- MariaDB-tietokanta
- PHP-sovellus (Drupal)
- Nginx-HTTP-palvelin
- MailHog-sähköpostikaappari
Koska Docker-kontit kärsivät macOS:ssä varsin huonosta tiedostojärjestelmäsuorituskyvystä, oli meillä kokoonpanossa mukana myös bg-sync-kontti, joka synkronoi tietokannan MariaDB-kontilta isäntäkäyttöjärjestelmän tiedostojärjestelmään. Noin jälkikäteen ajateltuna tämä oli huono ajatus, mutta tarkoitus oli hyvä: säilyttää tietokannan sisältö, vaikka Docker-virtuaalikone muuten tuhoutuisi.
Käytimme bg-synciä varsin pitkään tietokantakontin tietojen synkronointiin hyvin monen Drupal 8 -sivuston kanssa paikallisessa kehitystyössä. Tällä kokoonpanolla järjestelmän suorituskykyprofiili vaikutti kuitenkin todella erikoiselta: toisinaan hyvin raskaat operaatiot (kuten Drupalin välimuistin uudelleenrakentaminen) pyörähtivät kohtuullisessa ajassa, toisinaan ne puolestaan kestivät älyttömän pitkään ja pahimmillaan vetivät koko koneen kyykkyyn. Hyvin usein HyperKit vei loputtomasti prosessoriresursseja, eikä tilanne helpottanut muuten kuin sillä, että koko Docker-virtuaalikone käynnistettiin uudelleen. Hetkittäin taas kaikki näytti toimivan ihan mallikkaasti. Ongelmaa ei helpottanut se, että Applen koneiden jäähdytys ei ole missään määrin riittävä tällaisen kuorman käsittelyyn. Saimmekin jatkuvasti nauttia todella vahvasti lämpörajoitetuista prosessoreiden kellotaajuuksista, tulikuumista alumiinirungoista ja täysillä huutavista tuulettimista – kaikista samaan aikaan!
DTrace on huikea työkalu järjestelmien debuggaukseen ja valvontaan ja gnuplotilla datan visualisointi on helppoa ja nopeaa

Prosessorin käyttöhistorian visualisointi (visualisoinnin tylsä osuus)
Koska paikallisten kehitysympäristöjen suorituskykyongelmat alkoivat vaikuttaa todella kiusallisilta, päätin lähteä selvittämään, mistä kenkä oikein puristaa. Aloitin testin pystyttämällä itselleni vakiomuotoisen kehitysympäristön ja ajamalla siellä erään asiakkaamme sivustoa. Kellottelin jonkin verran raskaita sivustolla tehtäviä ylläpitotoimia, mutta lopputulokset olivat samat kuin ennenkin: täysin satunnaiset.
Jossakin vaiheessa vihdoin älysin kaivaa esiin macOS:n Järjestelmän valvonta -sovelluksen, joka osaa haluttaessa piirtää graafia mm. prosessorin käyttöhistoriasta. Oletuksenani oli, että raskasta ylläpito-operaatiota suoritettaessa prosessorin käyttö nousee pilviin, mutta homman valmistuttua tilanne tasaantuu takaisin normaaliksi. Näin ei kuitenkaan käynyt, vaan prosessorikuorma pysyi taivaissa todella pitkään vielä operaation jälkeen: operaatio saattoi valmistua 30 sekunnissa, mutta HyperKit käytti lähes kaikki prosessoriresurssit vielä kaksi minuuttia operaation valmistuttua. Hmm…
Osasimme epäillä ongelmakohdaksi tässä vaiheessa bg-sync-konttia, sillä tiedostojen synkronointi vaikutti oikeastaan ainoalta järkevältä selitykseltä ilmiölle. Tämä asia varmistui ctop-työkalulla, joka kertoi selvästi, että juuri ympäristön bg-sync-kontti oli se, joka kuormaa aiheutti. Tein vielä varmuudeksi kokeen, jossa sivustoa ajettiin kehitysympäristössä sekä ilman bg-synciä että sen kanssa. Tein kummallakin kokoonpanolla saman operaation, eli Drupalin välimuistin uudelleenrakennuksen. Tulokset näkyivät Järjestelmän valvonta -sovelluksen prosessorin käyttöhistoriassa seuraavasti:
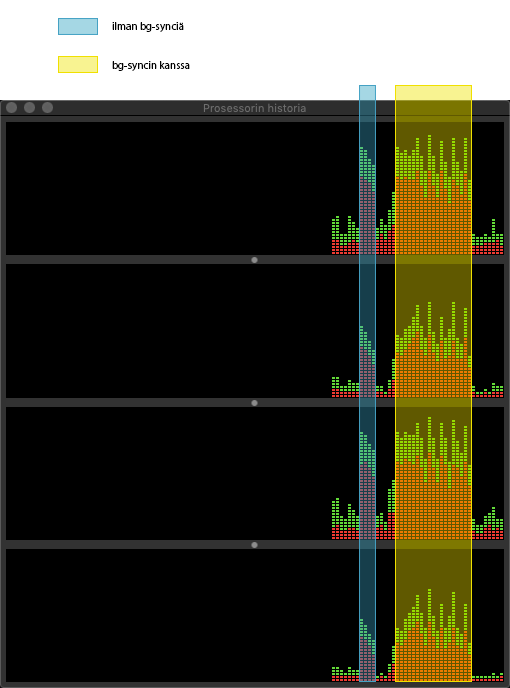
Ongelma aiheutui selvästi bg-sync-kontin käyttämisestä tietokannan tietojen synkronoinnissa isäntäkäyttöjärjestelmälle. Muistin lukeneeni HyperKitin GitHub-sivulta, että HyperKit tarjoaa macOS:n mukana tulevalle DTrace-työkalulle ns. luotaimet, joilla HyperKitin toimintaa voidaan instrumentoida. DTracella saisimme todennäköisesti tarkempaa tietoa siitä, mitä HyperKit tekee silloin, kun bg-sync-kontti touhuilee omiaan Drupalissa suoritettujen ylläpito-operaatioiden jälkeen.
Koska Docker-kontteja ajetaan virtuaalikoneella, tarvitaan niille myös virtuaalinen levy ja oma tiedostojärjestelmänsä. Isäntäkäyttöjärjestelmässä tämä näkyy yhtenä isona levytiedostona, jonka hypervisor sitten tarjoaa virtuaalikoneen käyttöön virtuaalisena levynä, eli lohkotallennustilana. Meidän tapauksessamme HyperKit hoitaa lohkojen lukemisen ja kirjoittamisen ja vieraskäyttöjärjestelmä sitten tuo mukanaan oman tiedostojärjestelmänsä, joka käyttää lohkotallennusrajapintaa. Tähän lohkotallennukseen liittyen HyperKit tarjoaa muutaman mielenkiintoisen luotaimen DTracelle: block-preadv ja block-pwritev, eli lohkoluku ja -kirjoitus.
HyperKitin levyoperaatioiden visualisointi (se mielenkiintoinen osa)
DTracella on oma yksinkertainen D-skriptauskielensä (ei tämä). D-skriptikieli on saanut hyvin vahvasti vaikutteita AWK-kielestä, mutta se ei ole kuitenkaan Turing-täydellinen. Olen elämäni aikana kirjoittanut noin kolme D-skriptiä, joten kovin syvällistä osaamista minulla ei DTracesta tai D-skriptikielestä ole, mutta tällaisissa varsin simppeleissä tapauksissa sitä ei onneksi todellakaan tarvita. Kirjoitin yhden D-skriptin, joka tulostaa viiden sekunnin välein rivin, jossa on menneeltä viideltä sekunnilta seuraavat tiedot:
- Kirjoitusoperaatioiden lukumäärä
- Lukuoperaatioiden lukumäärä
- Järjestelmän aikaleima sekunnin tarkkuudella
DTracen dynaaminen luonne ilmenee hienosti mm. siinä, että sen voi lennossa liittää käynnissä olevaan prosessiin ilman, että se vaikuttaa prosessin toimintaan mitenkään. Koska DTracelle pitää määritellä, mihin prosessiin se liitetään, täytyy ensin saada selville HyperKit-prosessin prosessi-ID. Tämä onnistuu näppärästi yhden rivin komentorivirimpsulla: ps -A | grep -m1 com.docker.hyperkit | awk '{print $1 "t" $4}'. Komennossa kolme eri ohjelmaa liittyvät toisiinsa putkilla seuraavasti:
-
ps -A: Listataan (myös) kaikki muiden käyttäjien käynnistämät käynnissä olevat prosessit, joihin ei ole liitetty terminaaleja. -
grep -m1 com.docker.hyperkit: Suodatetaan listasta ensimmäinen sellainen rivi, jossa on teksti ”com.docker.hyperkit”. -
awk '{print $1 "t" $4}': Tulostetaan riviltä välilyönneillä erotellut sanat 1 ja 4 siten, että niiden välissä on sarkainmerkki.
Komennon tuloksena on tekstirivi, jossa on ensin numero ja sen vieressä teksti ”com.docker.hyperkit”. Tuo numero on HyperKitin prosessi-ID, joka vaihtuu aina, kun HyperKit käynnistyy uudestaan.
Nyt kun saimme tietoomme HyperKitin prosessi-ID:n, voimme liittää D-skriptin DTracella prosessiin ja ohjata tulostuksen lokitiedostoon: sudo ./block_rw.d -p 1602 > block_rw.log. (Jos muuten ajelet näitä komentoja omalla koneellasi, muista vaihtaa tässä komennossa numeron 1602 tilalle oikea HyperKitin prosessi-ID.)
Tietojen keräämiseksi ei enää tarvinnut tehdä muuta kuin saada HyperKit tekemään hommia. Koska halusin saada molemmista kokoonpanoista (bg-syncin kanssa ja ilman) kerättyä vertailukelpoista tietoa, tein niillä molemmilla jälleen saman operaation, eli Drupalin välimuistin uudelleenrakennuksen. Tulokseksi tästä sain lokitiedoston, joka kyllä sisälsi mielenkiintoista dataa, mutta sitä oli hankala tulkita.
Datan tulkintaa varten halusin nopeasti visualisoida sen jotenkin. Olin juuri käyttänyt omassa kirpputorimyyntiseurannassani gnuplotia myyntigraafien piirtämiseen ja uskoin sen soveltuvan tähän käyttöön erinomaisesti. gnuplot on sovelluksena todella monipuolinen ja sillä pystyy erittäin pienellä vaivalla ja nopeasti visualisoimaan mitä moninaisimpia dataröykkiöitä. Kuten arvata saattaa, myös gnuplotia komennetaan sen omalla, yksinkertaisella skriptikielellä. gnuplot on sikäli hieno sovellus, että se pyrkii oletuksena tekemään melkein väkisin jotakin järkevää. Tämä ominaisuus tekee sen käyttämisestä erittäin ergonomista ja vaivatonta. gnuplotin yleisen järkevyyden lisäksi D-skriptin tuottama lokitiedosto oli jo valmiiksi hyvin gnuplotille sopivassa muodossa, joten visualisointi onnistui hyvin yksinkertaisella gnuplot-skriptillä. Skriptin tuloksena syntyi seuraavanlainen SVG-kuva:
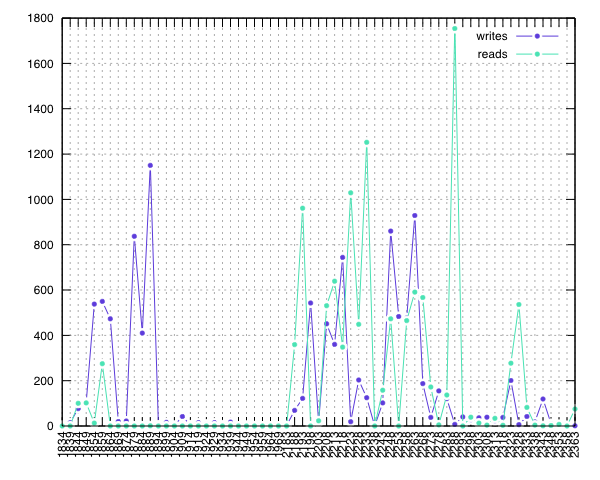
No huhhuh!! Samassa kuvassa näkyvät molempien kokoonpanojen aiheuttamat lohko-operaatiot omina jaksoinaan. Graafin alkuosa (1:llä alkavat aikaleimat x-akselilla) osoittaa, miten järjestelmä toimii ilman bg-sync-konttia ja loppuosa (2:lla alkavat aikaleimat) näyttää toimintaa bg-syncin kanssa. Varsinaisilla operaatioilla ei ollut kestossa juuri mitään eroa, mutta niiden aiheuttamassa kuormassa niin prosessorille kuin levyjärjestelmällekin eroa löytyi runsaasti. DTracen tuottamassa lokitiedostossa on näiden kahden jakson välillä pieni katkos, sillä pysäytin DTracen siksi aikaa, kun käynnistin ympäristön uudelleen toisella kokoonpanolla – dataa ei kuitenkaan ole manipuloitu, vaan lokipätkät on vain liitetty toisiinsa.
Johtopäätökset
Visualisointitarpeet tässä tapauksessa olivat hyvin yksinkertaiset ja samaan lopputulokseen oltaisiin päästy varmasti hyvin monellakin erilaisella ratkaisulla. Mielestäni tässä kuitenkin hyvin tulevat esiin niin DTracen kuin gnuplotinkin vahvuudet: DTrace on huikea työkalu järjestelmien debuggaukseen ja valvontaan ja gnuplotilla datan visualisointi on helppoa ja nopeaa. Yhdessä nämä työkalut mahdollistavat hyvin tarkan järjestelmävisualisoinnin, joka auttaa ymmärtämään ja selvittämään ongelmia sekä tarjoaa tukea päätöksille.
Tämän tutkimuksen perusteella oli varsin perusteltua lopettaa tietojen synkronoiminen tietokantakontilta isännälle. Nyt kehitysympäristöjen tietokannat tuhoutuvat, mikäli Docker-virtuaalikone joudutaan luomaan uudestaan tai sille tapahtuu jotakin muuta pahaa. Tästä ei kuitenkaan aiheudu meille ongelmia, sillä kehitysympäristöjen on tarkoitus aina ollakin vain tilapäisiä ja kaikki kehitystyön kannalta oikeasti tärkeä data kulkee versiohallinnassa.
Meidän macOS:ssä ajettavat kehitysympäristömme toimivat nyt paljon aikaisempaa kevyemmin ja nopeammin. Tämän johdosta kehittäjätyöasemamme pysyvät nopeampina ja viileämpinä, käyttävät vähemmän virtaa ja kestävät pidempään. Ongelma ei johtunut bg-syncistä, vaan siitä, miten me sitä käytimme. macOS ei ole täydellinen alusta Docker-konttien ajamiselle laitteistotason virtualisoinnin vuoksi, mutta se on riittävän hyvä kehityskäyttöön.
Eli lyhyesti: kyllä, onhan se huono idea synkronoida tietokantaa virtuaalikoneella ajettavasta Docker-kontista isäntäkäyttöjärjestelmälle.


